Tracking failure metrics such as MTBF (Mean Time Between Failures), MTTR (Mean Time to Repair) and MTTF (Mean Time to Failure) is the quickest way to cut downtime and raise equipment efficiency. In this Resco guide you will find clear definitions, the formulas you need to calculate each metric with your own data, and practical advice on turning the results into a preventive-maintenance plan inside Resco Field Service, Resco Inspections and Resco Power Forms.
If you prefer a short visual overview first, watch our three-minute explainer video that compares MTBF, MTTF and MTTR in one place.

Reactive maintenance erodes profit margins in sectors such as manufacturing, utilities, mining and food processing. By moving to a data-driven preventive approach with Resco’s offline-ready mobile apps, you can transform these metrics into everyday KPIs that lower costs, reduce risk and extend asset life.
The guide below shows how each indicator works, demonstrates the calculations step by step and highlights the efficiency gains that come from capturing field data with Resco in real time.
Download a free Preventive Maintenance template to inspect the state of the equipment or machinery
What is MTBF (Mean Time Between Failures)?
Mean Time Between Failures (MTBF) is a measurement of the average time between failures of something that can be fixed. The average time between system failures is known as mean time between failures (MTBF).
MTBF is an important maintenance parameter for:
- evaluating performance,
- evaluating safety,
- evaluating equipment design (particularly for critical or complex assets such as generators or airplanes),
- assessing an asset’s dependability.
MTBF is also one part of the availability formula, along with mean time to repair (MTTR). The MTBF calculation only considers unscheduled maintenance and ignores routine maintenance such as inspections, recalibrations, and preventive part replacements.
The Mean Time Between Failures (MTBF) is a maintenance metric that reflects how long equipment can operate without being disrupted. This pertains to the equipment’s availability. Uptime, or availability, is one of the most important indications of total equipment efficacy and is always a priority area for increasing productivity.
The MTBF and another statistic, the MTTR, can be used to calculate the overall uptime of a piece of equipment (mean time to repair). It’s worth noting that MTBF only applies to repairable devices. It can be used to plan for scenarios that necessitate the maintenance of critical equipment in manufacturing operations. Knowing this information allows you to make informed decisions for your plant.
Failure is a problem, and learning everything there is to know about a problem is frequently the most effective way to fix it. Measuring MTBF is one approach to learn more about a failure and limit its consequences. An MTBF study can help your maintenance crew reduce downtime, save money, and work more efficiently.
The Mean Time Between Failure (MTBF) is a measure of how likely an asset is to fail within a given time frame or how frequently a specific form of failure is expected to occur.
It will help you avoid costly breakdowns when combined with other maintenance tactics such as failure codes and root cause analysis, as well as extra maintenance metrics such as MTTR. Having this information makes it easier to build preventive maintenance (PM), allowing for greater reliability by addressing issues before they become a failure.
If a failure occurs, having all of the information allows you to increase maintainability.
How to calculate MTBF (Mean Time Between Failures)
MTBF=total number of operational hours / total number of failures
To calculate MTBF, divide the total number of operational hours in a period by the number of failures that occurred during that period. The most common unit of measurement for MTBF is hours.
Example: An asset could have been operational for 1,000 hours over the course of a year. That asset failed eight times during the course of that year. As a result, the equipment’s MTBF is 125 hours.
You must collect data from the equipment’s actual performance in order to obtain an accurate measure of MTBF. Human variables such as design, assembly, and maintenance, among others, determine how each asset performs under varied conditions.
As a result, you should avoid basing your maintenance decisions on a manual’s MTBF estimate.
Calculating an asset’s MTBF gives you a starting point for planning out your preventative maintenance. You can schedule PM ahead of time if you know how frequently an asset fails.
This increases your chances of preventing failure and maximizing your resources by requiring as little maintenance as feasible. This approach to condition-based maintenance is an excellent first step.
How to improve MTBF
A well-planned preventative maintenance program can significantly increase your MTBF. When it comes to maintenance, whenever you can be proactive rather than reactive, you have a better chance of preventing failures.
A badly implemented preventative maintenance program can actually reduce MTBF. Quick breakdowns can be caused by a lack of training, a lack of or poorly prepared manuals, and checklists.
Understanding why something went wrong is the key to preventing it from happening again, or at least not as frequently. Root cause analysis, similar to preventive maintenance, can boost MTBF indirectly by identifying a long-term solution.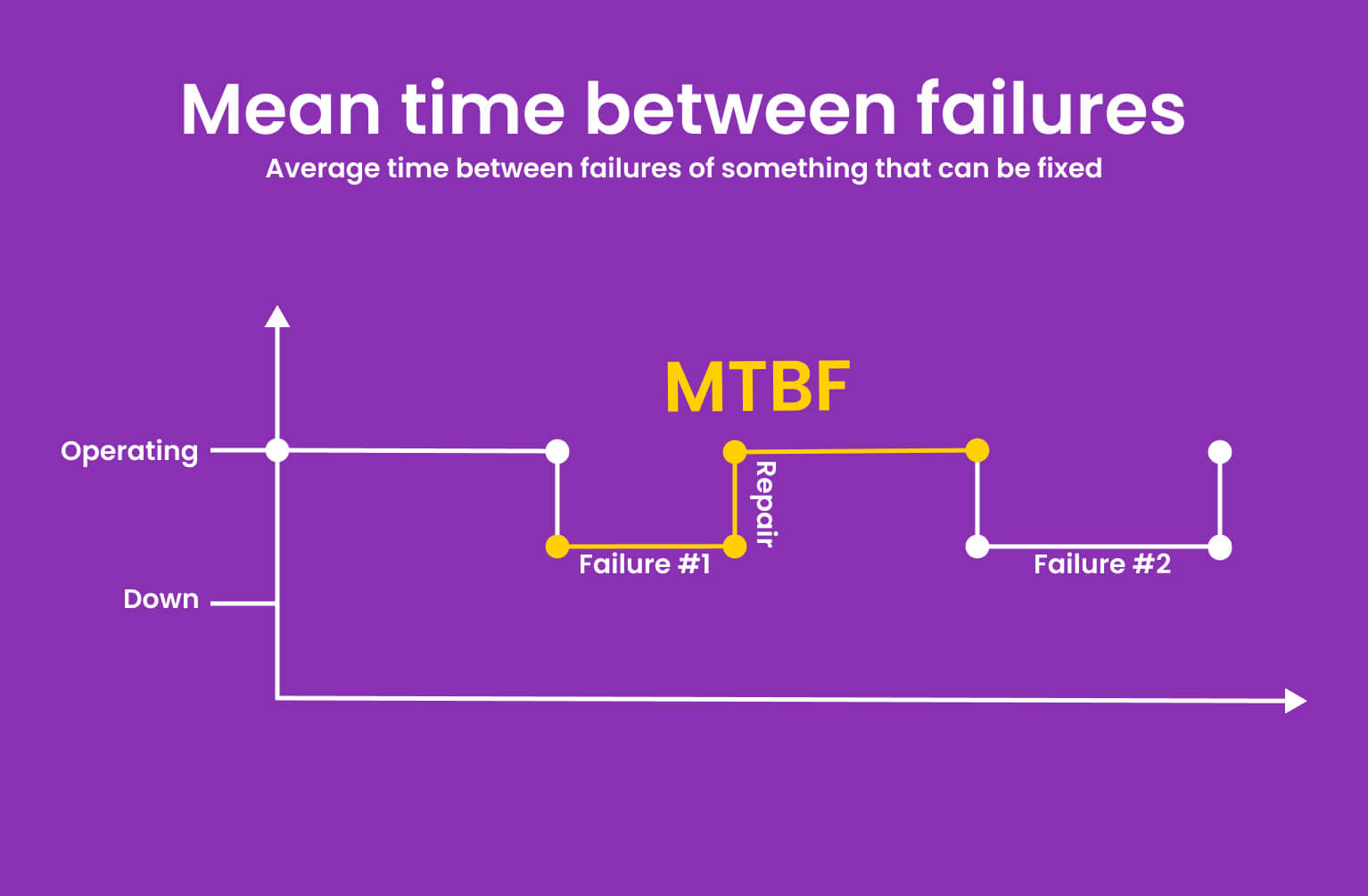
If a component fails regularly, for example, you can consider replacing it with a higher-quality component.
You can potentially boost MTBF and reduce downtime if you have the ability to implement an early warning system to detect equipment faults before they lead to failure.
While establishing a condition-based maintenance plan isn’t always straightforward, you can begin by implementing a complete productive maintenance strategy.
Key takeaway: One technique to start conquering unplanned downtime at your facility is to calculate mean time between failures. An asset can fail for a variety of reasons. The first step in diagnosing and treating a problem is to take inventory of the symptoms.
This can be accomplished by tracking and evaluating the Mean Time Between Failures (MTBF). Taking steps to increase your assets’ MTBF and reliability can have a significant influence on your business, from the shop floor to the executive suite.
What is MTTF (Mean Time To Failure)?
The mean time to failure, or MTTF, is a measurement of how long it takes for something to fail. This is a device’s average life expectancy. The mean time to failure is derived by multiplying the device lifespans by the number of devices.
The average amount of time a non-repairable asset operates before failing is measured by the mean time to failure (MTTF). Because MTTF only applies to assets and equipment that can’t or shouldn’t be fixed, it’s often referred to as an asset’s average lifespan.
The MTTF applies to non-repairable assets, which are replaced when they fail. There are a variety of reasons why an asset might not be fixed, but the most typical argument is that replacing the asset is less expensive and takes less time.
Replacing a tire that costs a few hundred dollars in parts and labor, for example, is likely more cost-effective than removing the wheel and attempting to fix it. It simply isn’t worth the time or money.
Examples of this type of equipment:
- transistors,
- fan belts in motors and engines,
- idler balls/rollers on conveyor belts,
- forklift wheels,
- lightbulbs, etc.
These assets may be used in run-to-failure, preventive, or condition-based maintenance programs.
In circumstances when regular preventive maintenance can extend the life of a part and a larger, mission-critical asset, MTTF can be used to schedule maintenance on non-repairable assets. For example, on a larger machine, lubricating bearings.
It can also be utilized to make purchase decisions for parts and equipment. Higher-quality and more durable materials will result in a longer MTTF, which means less money will be spent on purchasing new parts and replacing old ones.
The MTTF can be useful in developing a just-in-time inventory strategy. If a facility knows a part’s MTTF is 10,000 hours and getting a replacement takes 100 hours, they can order a part every 9,900 hours.
How to calculate MTTF (Mean Time To Failure)
MTTF= total number of operational hours / total number of assets in use
To calculate MTTF, divide the total number of hours of operation by the total number of assets in use.
MTTF = Total hours of operation ÷ Total assets in use
MTTF = 10,000 hours ÷ 40 assets
MTTF = 250 hours
Since MTTF indicates the average time to failure, calculating it with a larger number of assets will yield a more accurate result. Let’s imagine you wish to compute the MTTF of your facility’s conveyor belt rollers. There are 125 identical rollers that have completed 60,000 hours of service in the last year. This is how your MTTF calculation might look:
MTTF = Total hours of operation ÷ Total assets in use
MTTF = 60,000 hours ÷ 125 assets
MTTF = 480 hours
You can estimate that a roller’s average life expectancy at your facility is 480 hours.
How to improve MTTF (Mean Time To Failure)
The key to increasing MTTF is to monitor it. Monitoring ensures that if something goes wrong, you have the information you need to quickly identify and fix the problem.
Tools like Resco Inspections help monitor asset health by enabling structured, in-field data collection. Capturing recurring issues or wear signs during inspections supports better planning and extends asset lifespan.
Metrics, logs, and distributed tracing provide a strong foundation for troubleshooting equipment and application issues. By incorporating these into your monitoring process, your team will be able to identify the problem’s root cause more quickly and plan a course of action from there.
Always buy your assets and parts from reputable manufacturers. Invest in materials that are produced in strict accordance with quality standards. You’ll have materials that are long-lasting and will serve you for a long time.
It is not enough to buy high-quality materials; you must also use the assets and parts only for the purposes for which they were designed. Also, make sure that the voltage, pressure, heat, and humidity are all in good working order. Always have qualified professionals install your assets.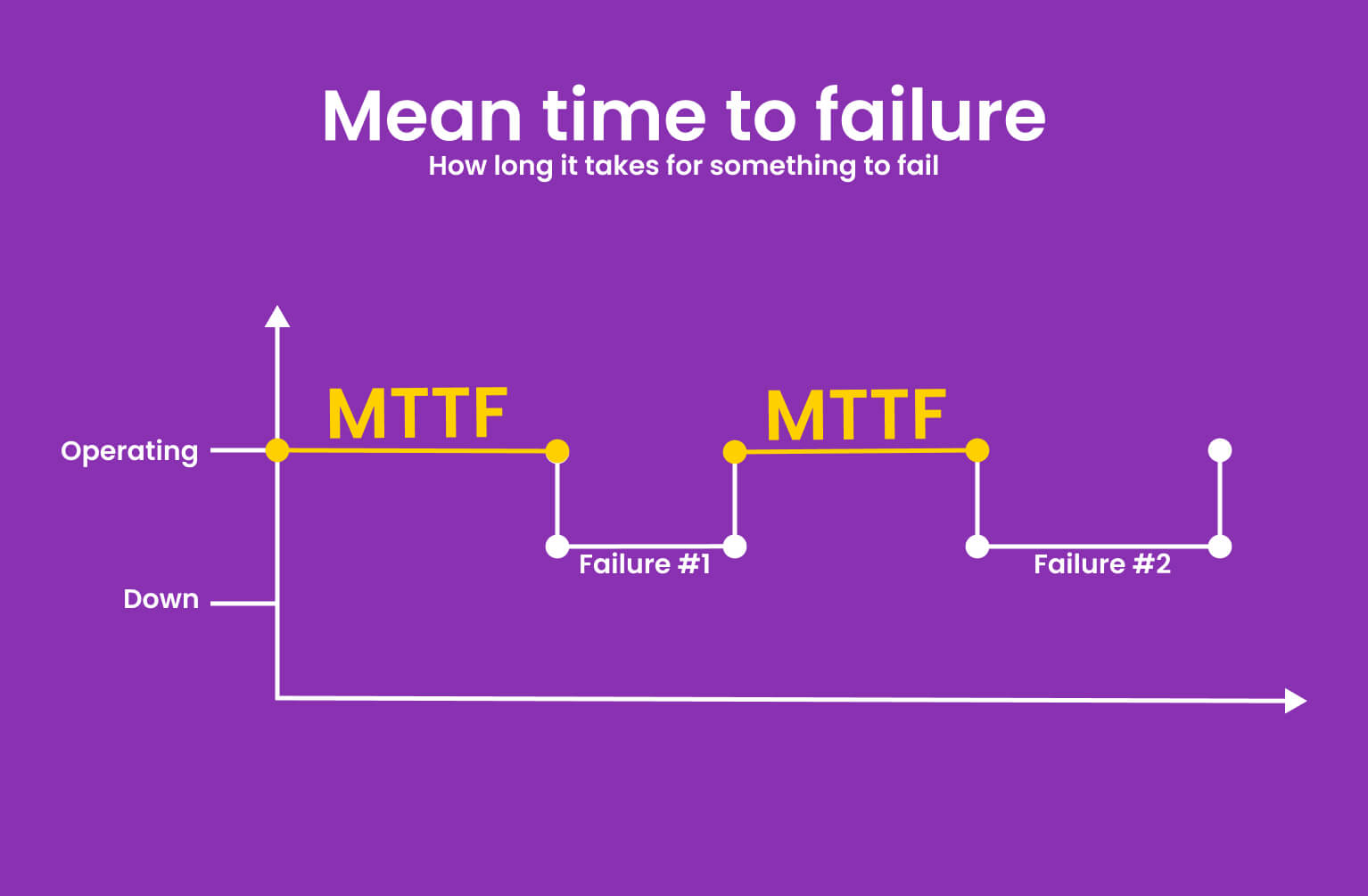
Because there’s little that maintenance scheduling can do for assets on the verge of failure, implement an effective preventive maintenance program. Preventive maintenance operations such as cleaning and lubrication, on the other hand, might help them last longer.
Increasing your MTTF can be as simple as creating and implementing a successful PM program. Proper inventory control can also aid increase MTTF to some extent. When you overstock merchandise and commodities in the warehouse for an extended period of time, they are more prone to become damaged, rusted, or expire. Faulty equipment and parts will only last a limited time before they break down.
Understand the importance of an accurate MTTF in avoiding or minimizing outages, but don’t treat it like a single statistic. When paired with mean time between failures (MTBF) and mean time to repair (MTTR), MTTF is more useful to enterprises.
If no reaction team is available to repair broken components rapidly, a full warehouse of spare parts is useless. Replacing broken components isn’t always enough to restore systems and applications to full functionality and health. When you combine MTTF and MTTR, you can save repair time by replacing parts before they fail.
Key takeaway: When a single component (such as a fan belt) fails, it can cause a motor to fail, shutting down an entire system or production line. Knowing when that component will fail and replacing it before it does is critical to reducing costly repairs, minimizing downtime, and maximizing equipment longevity.
Reduced reliance on reactive maintenance and enhanced predictive or planned maintenance are two factors that can help organizations reduce downtime and establish stronger maintenance plans.
What is MTTR (Mean Time To Repair)?
MTTR is an acronym that stands for mean time to repair, mean time to recovery, mean time to resolution, mean time to resolve, mean time to restore, or mean time to reply.
In all contexts, the word reflects the average time required to troubleshoot and remedy an issue. The average time it takes to fix (and restore) a system once a failure is found is known as the mean time to repair.
The average time it takes to repair and return a component or system to working state is referred to as the mean time to repair.
As a result, MTTR is a key indicator of an organization’s ability to maintain its systems, equipment, applications, and infrastructure, as well as its efficiency in repairing such equipment in the event of an IT outage.
The MTTR starts when a fault is discovered and includes:
- diagnostic,
- repair,
- testing,
- other actions until the service is returned to end users.
A short mean time to repair (MTTR) suggests that a component or service can be repaired quickly, and that any IT difficulties related with it will most likely have a minimal impact on the business. A high MTTR indicates that a device failure could cause a major service outage, affecting the business more significantly.
Because MTTR ostensibly gauges how long business-critical systems are down, it’s a good predictor of the financial effect of an IT disaster. When IT problems occur, the higher the MTTR of an IT team, the greater the risk of business disruptions, customer discontent, and revenue loss.
It is unavoidable for technology to fail. Understanding the Mean Time to Repair (MTTR) gives businesses a sense of how fast and efficiently they can anticipate to respond to breakdowns and resume normal operations. Lower MTTR rates, on the whole, indicate a healthy computing environment and a successful IT function.
How to calculate Mean Time To Repair (MTTR)
MTTR= total repair time / total number of repairs
The first step in calculating MTTR is to figure out how much time you spend repairing an asset during a given time period.
Example: Assume you have a press with a challenging motor. You worked on it for four hours over the course of a week. You work on it for an hour and a half the first time.
Then you’ll need another two and a half hours for the second time. In this situation, the lengths of time required to repair the asset are fairly comparable. This isn’t always the case, though. With highly varying repair times, you can still use MTTR.
So, on another asset, you needed thirty minutes the first time you corrected it. Three hours the second time. It’s the third time, and it’s been two days.
The total downtime caused by failures is divided by the total number of failures to get the MTTR. For example, if a system fails three times in a month, resulting in a total of six hours of downtime, the MTTR will be two hours.
Reducing Mean Time To Repair (MTTR)
While many of the issues that contribute to a high MTTR are unique to each organization (requiring a thorough examination of its own IT processes and procedures), there are certain fundamental approaches to reduce MTTR that will benefit every company.
To begin lowering MTTR, you must first gain a deeper understanding of your occurrences and failures. Modern business software can assist you in automatically uniting your siloed data to establish a valid MTTR measure and gaining useful insights into the causes and contributions to this critical metric.
Another key factor is how efficiently your field teams respond once an issue is identified. With Resco Field Service, organizations can optimize dispatching, track technician availability in real time, and ensure the right person arrives with the right tools and data. This leads to faster on-site resolutions, shorter repair cycles, and ultimately lower MTTR.
You must then identify the issue before you can remedy it, and the sooner you do so, the better. A good monitoring solution will provide a continuous stream of real-time data about your system’s performance, usually in the form of a single, easy-to-understand dashboard interface, and will notify you of any concerns as they arise.
While impromptu replies are frequently required for smaller, resource-constrained businesses, large corporations should adhere to more stringent procedures and protocols. For many businesses, this will necessitate a traditional IT service management (ITSM) strategy with clearly defined roles and reactions.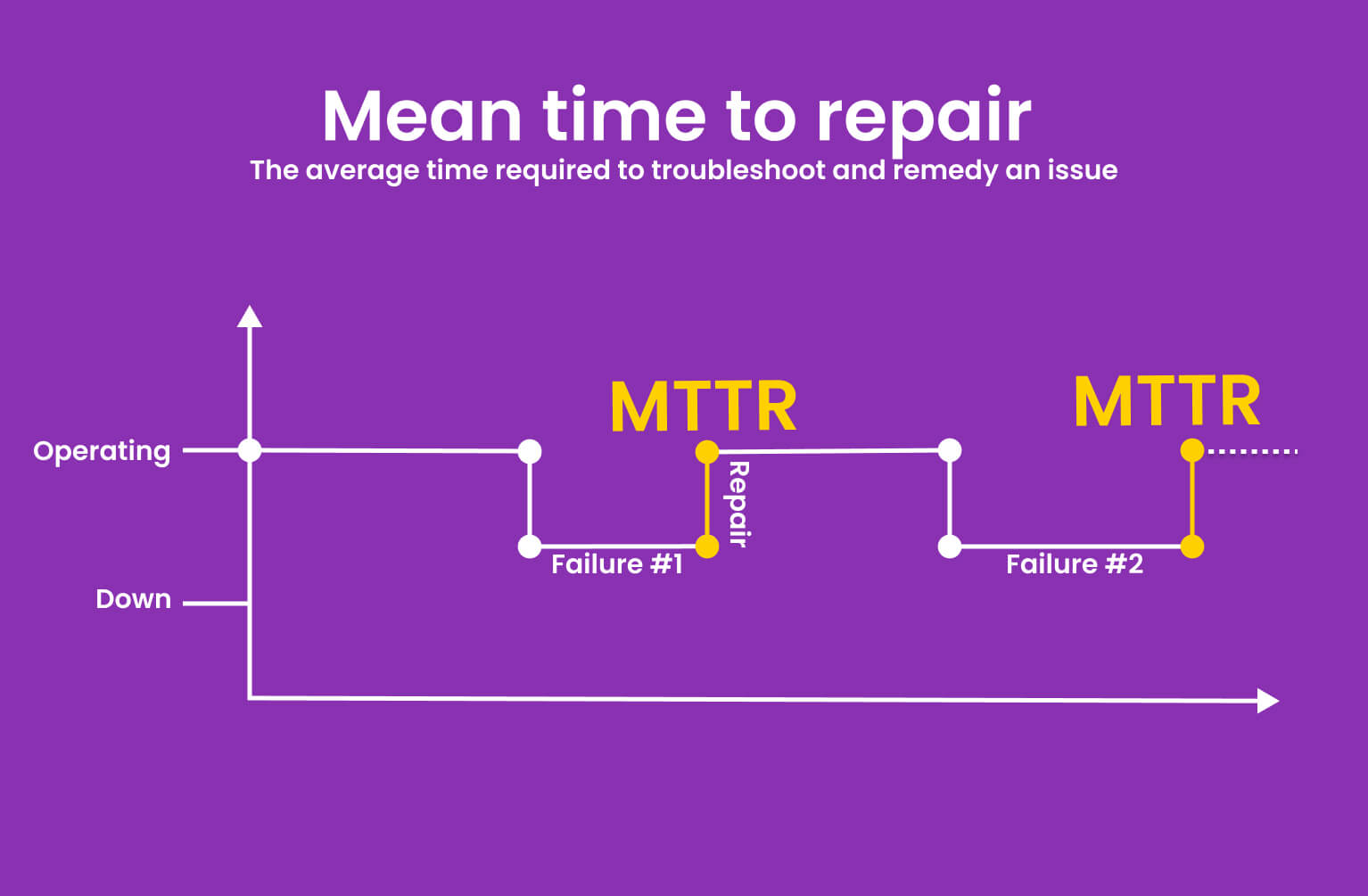
Companies that have successfully completed a comprehensive digital transformation may be able to take a more flexible strategy, utilizing cross-functional communication tools and developing tailored solutions to each occurrence. Whatever strategy you have in place, make sure it specifies who to contact in the event of an incident, how to document the problem, and what steps to take as your team works to resolve it.
A speedy response begins with ensuring that the correct people are informed about a situation as soon as possible. For low-priority situations during business hours, a phone call to a team member may suffice. But what if your website goes down due to a failing server at 8 p.m. on a Friday?
An automated incident-management system may deliver multi-channel notifications — phone calls, text messages, and emails to all designated responders at the same time, saving time that would otherwise be spent manually locating and contacting each person.
It’s priceless to have dedicated knowledge specialists on your incident-response team. However, if you rely only on these experts for minor issues, you risk overburdening them, which might affect their ability to fulfill their regular duties and eventually lead to burnout.
Your response team may be limited if that specialist isn’t available during the incident. By ensuring that all team members have a thorough understanding of your system and are trained across numerous tasks and incident-response responsibilities, you can prevent these concerns and, in turn, reduce your MTTR.
When an issue arises, your team will be in a better position to respond more effectively, regardless of who is on call. This visibility into your infrastructure can aid in the faster and more accurate diagnosis of issues.
Having real-time statistics on the volume of incoming queries and how quickly the server responds to them, for example, will help you troubleshoot an issue if that server fails.
Data also helps you to understand how certain actions to repair system components affect system performance, allowing you to come up with a more rapid solution.
Key takeaway: While MTTR isn’t a magic figure, it is a good sign of a company’s capacity to respond to and resolve potentially costly issues swiftly. Given the direct impact of system downtime on productivity, profitability, and customer confidence, any tech-centric organization must have a thorough understanding of MTTR and its roles.
Bonus tips on more common failure metrics
What is MTTR (Mean Time To Recovery)?
MTTR stands for Mean Time To Recovery, although it can also refer to other failure management KPIs (key performance indicators). Because of the many possible interpretations, it is best to include the entire names to avoid any misunderstandings.
The average time it takes to recover from a product or system failure is known as the mean time to recovery (or mean time to restore). It is a critical measure in incident management since it indicates how swiftly you resolve downtime problems and restore service to your systems.
The time to recovery (TTR) is the whole length of the outage, from when the system fails to when it is fully operational again. The MTTR for a specific system is calculated as the average of all periods it takes to recover from failures.
What is MTTR (Mean Time To Resolve)?
The average time it takes to completely resolve an incident, including recognizing the problem, fixing the effects, and taking steps to prevent the event from happening again, is called Mean Time To Resolve.
Because it goes beyond downtime and includes work after the outage is resolved, the mean time to resolve statistic provides a wonderful insight into the whole breadth of fixing and resolving events.
The time to resolve is the amount of time that passes between the start of an occurrence and its conclusion. The mean time to resolve is calculated by taking the average of all incident resolve times.
What is MTTR (Mean Time To Respond)?
The average time required to restore a system to operational state after getting notification of a breakdown or cyberattack is referred to as Mean Time To Respond (MTTR). The Mean Time to Respond does not account for the time when a problem was already there but was not recognized.
The Mean Time to Detect is the name given to this period (MTTD). The overall duration of a cyberincident is equal to the sum of the MTTR and MTTD.
This metric allows you to understand how much of the recovery time is due to warning systems and how much is due to the repair team’s real effort.
To calculate the MTTR, gather data on all incidents over a given time period, add up the time spent recovering the system from the time the problem signal was received, and divide the total by the number of occurrences.
Example: Over the course of a month, a corporation suffers three cyberattacks. The first event took 20 minutes to minimize, the second 32 minutes, and the third 44 minutes. The monthly mean time between failures is (20 + 32 + 44)/3 = 32 minutes.
What is MTTA (Mean Time To Acknowledge)?
The average time it takes for the team in charge of the given system to acknowledge an occurrence from the time the alarm is issued is known as the Mean Time To Acknowledge.
The main purpose of MTTA is to track team responsiveness as well as the efficiency of the alert system. If your staff is bombarded with alerts, they may feel overwhelmed and respond to vital alerts later than desired.
This is known as alert fatigue, and it is one of the most serious issues in event management. It can be tracked and accessible owing to MTTA, therefore it won’t be a problem.
In Incident Management, MTTA is one of the KPIs (key performance indicators). Learn more about MTTR and other key performance indicators.
The time between when an alert is received and when it is recognized by the team is known as the time to acknowledge (TTA). The MTTA for a specific system is calculated by taking the average of all times it took to recognize event alarms.
Example: If a system went down in two consecutive events and it took the team 3 minutes to notice the first one and 7 minutes to acknowledge the second, the team’s MTTA would be 5 minutes.
What is MTBSI (Mean Time Between Service Incidents)?
The MTBSI report averages the uptime and downtime between service model component failures using the following formula:
MTBSI=(uptime+downtime) / number of service issues
(All values during a single summarization period)
A service incident is a complete transition cycle that begins with a down state, includes any number of ignored states, one or more up states, and ends with the following down state.
The Metric MTBSI (Mean Time Between System Incidents) is used to measure and report reliability. The mean time between failures of a system or IT service is referred to as the MTBSI. MTBSI = MTBF + MTRS MTRS (Mean Time to Restore Service.)
What is MTTD? (Mean Time To Detect)?
The average length of time it takes to detect or discover an issue (MTTD) is a key performance indicator (KPI) for IT Incident Management.
It calculates the time between the start of a system outage, service failure, or any other revenue-generating activity and the time it takes a DevOps or Incident Management team to detect the problem.
MTTD= total number of occurrences /time to discover the issue
To calculate MTTD, take the total number of occurrences over a certain time period and divide it by the time it took the team to discover the issue.
Example: If the incident occurred at 8:00 a.m. and the team discovered it at 8:15 a.m., the time to detect is 15 minutes.
It’s simple to calculate the mean time to detect by averaging over a period of time (2 weeks, 1 month, 1 quarter, 1 year) (MTTD).
What is MTTI (Mean Time To Identify)?
The mean time to detect faults in service or component performance is known as the MTTI.
MTTI is powered by proactive monitoring capabilities that allow for speedy validation and triaging of client complaints in order to determine the best course of action. You must monitor, evaluate, and review speed of response in order to consistently resolve issues addressed at the Service Desk.
Issues can be found, for example, by looking at the status of an application or component on a monitoring system dashboard or a cloud service status page, or by looking at transaction trends that suggest deviations from normal, such as a large decline in attempts or successes, or a spike in failures.
Reducing service unavailability and performance degradation, as well as incident costs, are all advantages of better MTTI at the Service Desk. Improving consumer perceptions of how problems and requests are handled, as well as your reputation.
What is MTTK (Mean Time To Know)?
The average time it takes for a corporation to learn that its security has been breached is referred to as the Mean Time To Know (MTTK).
The longer it takes you to discover you’re being phished, the more successful the phishing attempt will be. There isn’t much time to react in the event of a phishing assault.
Most phishing-related damage occurs within the first two hours. Reducing your MTTK improves your ability to detect breaches quickly, significantly minimizing potential harm.
The greater the damage to your brand, the more successful the phishing attack. A successful phishing assault might have the most expensive consequences.
Customers’ trust can be lost over time, preventing them from purchasing or doing business with your firm for years, if they return at all. A high MTTK indicates that you have no control over what’s going on in your internal security environment.
What is MDT (Mean Down Time)?
The average total downtime required to return an asset to full operational capability is known as Mean Downtime (MDT). MDT refers to the time it takes from when an asset is reported as down to when it is returned to operations / production to operate.
MDT includes:
- administrative time for reporting,
- logistics and materials procurement,
- equipment lock-out/tag-out for repair or preventive maintenance, etc.
Differences Between Key Failure Metrics
MTTF vs MTBF vs MTTR (Mean Time To Failure vs Mean Time Before Failure vs Mean Time To Repair)
Mean time to failure (MTTF) although sounds similar to mean time between failure (MTBF), the two metrics are not the same. The type of asset employed in the calculation is a significant distinction.
MTTF deals with non-repairable assets, whereas MTBF deals with assets that can be quickly repaired without spending a lot of money when they break down. The mean time to failure (MTTF) is a statistic for non-repairable devices, such as light bulbs, that have a useful life before being discarded once they fail.
For repairable systems, the mean time between failure (MTBF) is utilized. It’s the average time between failures in a certain operation.
It’s critical to remember that this average is based on the system’s whole useful life. MTBF is the most plausible estimator for the rate in a homogeneous Poisson process since it is an average across the system lifetime.
As a result, MTTF and MTBF are reciprocals of the failure rate for a non-repairable device or a repairable system, respectively. This enables us to calculate dependability (the likelihood of a device or system not failing) over any time span.
A failure function and a restore function are both available in repairable systems. The failure function is estimated using approaches such as MTTF and MTBF.
The probability that the system will be restored to service in a certain amount of time is known as maintainability (MTTR). It’s a method for calculating the restoration function.
In a Markov chain, the MTBF and MTTR indicate two independent processes: failure and restoration.
Their sum is nonsensical (e.g., MTBSI is a meaningless measure), but when MTBF and MTTR are presented separately, useful information about the failure and repair functions emerges.
Preventative Maintenance Checklist
Download a free Preventive Maintenance template to inspect the state of the equipment or machinery
MTTD vs MTTI (Mean Time To Detect vs Mean Time to Identify)
Depending on your firm and the context, mean time to detect and mean time to identify are often used interchangeably.
Mean Time to Identify (MTTI) and Mean Time to Detect (MTTD) are crucial measures that can help an organization get visibility into its performance and identify areas for development. Mean Time to Detect (MTTD) is another name for MTTI.
MTTD vs MTTA (Mean Time To Detect vs Mean Time To Acknowledge)
The processes of detecting and admitting occurrences and failures are similar, but they differ in the human element. Most of the time, MTTD is a calculated measure that platforms should inform you of.
MTTA adds a human dimension to this, taking MTTD and having a human admit that something has gone wrong.
While the algorithms for detecting anomalies and issues are quite accurate, they are still the result of a machine-learned algorithm, and a human should double-check that the discovered issue is, in fact, an issue.
MTTF vs MTTR (Mean Time To Failure vs Mean Time To Repair)
The mean time to failure is a measurement of how long it takes for something to fail. The mean time to repair is a measurement of how long it takes to get a system up and running again.
This results in an unfair comparison because the variables being measured are vastly different. Let’s consider the case of automobiles. Let’s envisage your Toyota RAV4 2021 is involved in an accident.
The MTTF can be estimated as the time it takes from the time of the accident to the time you obtain a new car. The MTTR is the time it takes for a car to be repaired from the time it gets involved in an accident.
MTBF vs MTTR (Mean Time Before Failure vs Mean Time To Repair)
The terms “MTBF” and “MTTR” are used to describe separate steps in a broader process. The time between failures for devices that need to be repaired is measured by MTBF, while the time it takes to repair those devices is measured by MTTR.
In other words, MTBF assesses a device’s dependability, whereas MTTR assesses the effectiveness of its repairs.
MTTF vs MTTR (Mean Time To Fix vs Mean Time To Repair)
Because they both measure the average time necessary to troubleshoot and repair failing equipment and represent how quickly an organization can respond to unanticipated breakdowns and repair them, the terms mean time to fix and mean time to repair are interchangeable.
The main distinction is that most situations employ mean time to repair (MTTR) rather than mean time to fix (MTTF).
MTRS vs MTTR (Mean Time To Restore Service vs Mean Time To Repair)
The mean time to restore service is similar to the mean time to repair service, but it only covers the period from when repairs begin to when full functionality is restored, rather than the time from failure to resolution. In general, MTTR isn’t very useful as a KPI.
It will inform you about your repair procedure and how efficient it is, but it will not tell you how much your users are suffering as a result of it. If it takes three months to locate the broken drives, and they are slowing down your system for your users, a 5.3-minute MTTR is neither useful nor impressive.
Customers are usually more concerned with the overall amount of time their gadgets are down than with the repair time. They want to spend as little time as possible down.
Final thoughts
Failure metrics like MTBF, MTTF, and MTTR are more than just technical indicators. They offer valuable insights into how reliable your operations are, how quickly your team responds, and how efficiently you manage repairs and maintenance. Each metric highlights a different aspect of performance, from asset lifespan to downtime recovery.
But to truly unlock their value, these metrics need to be connected to live operational data and daily workflows. That is where Resco comes in.
With Resco Inspections, you can capture equipment condition data directly from the field, even offline. Resco Field Service helps optimize technician scheduling, track availability in real time, and ensure the right person with the right tools gets to the job site. Resco Power Forms allows you to standardize the way you document inspections, failures, and repairs.
By integrating these digital tools, you turn your failure metrics into actionable insights. This leads to faster response times, reduced downtime, better resource allocation, and more predictable maintenance cycles.
Pro tip: Start integrating failure metrics into your maintenance routine today. When paired with the right mobile solutions from Resco, these metrics become powerful drivers of reliability, efficiency, and continuous improvement across your organization. To get started, download the Preventive Maintenance Checklist or request a free demo and see how Resco can streamline your maintenance strategy.